
Privacy is Normal and the Path to Value in an Agentic Everything Era
Why privacy-preserving identity and value isn’t optional…it’s optimal

It’s becoming clear that AI agents will be everywhere.
They’re booking your calendar, negotiating deals, managing your finances both on and off chain, sharing intelligence and contributions to research, and handling your health data. Soon they’ll be making decisions you don’t even see, coordinating with other agents, executing transactions, representing you across networks you’ve never heard of. Adding the A to DAO for all the networks you participate in.
This is the agentic everything era. And it changes the entire game for identity and money.
If agents are going to act on your behalf, privacy isn’t a feature… It’s the foundation.
Agents are going to converge on what is ‘value’, bringing information and money together closer than ever before.
Without privacy, your agent isn’t yours. It’s the platform’s agent, watching, learning you, ultimately building you into the npc in a simulation.
Privacy is normal. It always has been. Now more than ever.
The question is whether we build systems that respect this, or keep pretending surveillance is somehow more valuable.
Spoiler: The math shows it’s not.
*this article is the start of me trying to ‘math’ the concept out into a model so we can prove or disprove it as a function for agents to check over time, perhaps build it to be a machine-readable, verifiable credential scoring system for privacy. Also, this could probably follow a more academic path to prove out, i’m certainly open to that, but just wanted to get the concept down here first. comments and suggested improvments are welcome*

Why Agents Need Privacy to Function
Let’s think about what an agent actually does.
Your AI assistant needs to prove your identity across different platforms without leaking your entire history. It needs to negotiate on your behalf without revealing your bottom line. It needs to coordinate with your doctor’s agent, your bank’s agent, your employer’s agent, all while keeping your data private.
This isn’t a luxury for cypherpunks to advocate anymore. This is going to be the basic functionality.
Without privacy:
Your agent can’t negotiate effectively (the other side sees everything)
You can’t verify what it’s doing (black box controlled by platforms)
Every interaction leaks data that gets sold, aggregated, and weaponised
You have zero recourse when things go wrong
With privacy:
Zero-knowledge proofs let your agent prove claims without revealing data
Self-sovereign identity means you control the keys, not the platform
Verifiable credentials create audit trails without surveillance
Cryptographic protection ensures your agent acts for you, not against you
The infrastructure for this exists. DIDs, ZK proofs, verifiable credentials, hardware wallets, encrypted compute, privacy-preserving blockchains. It’s not theoretical. It’s shipping.
The question is: what’s it worth?
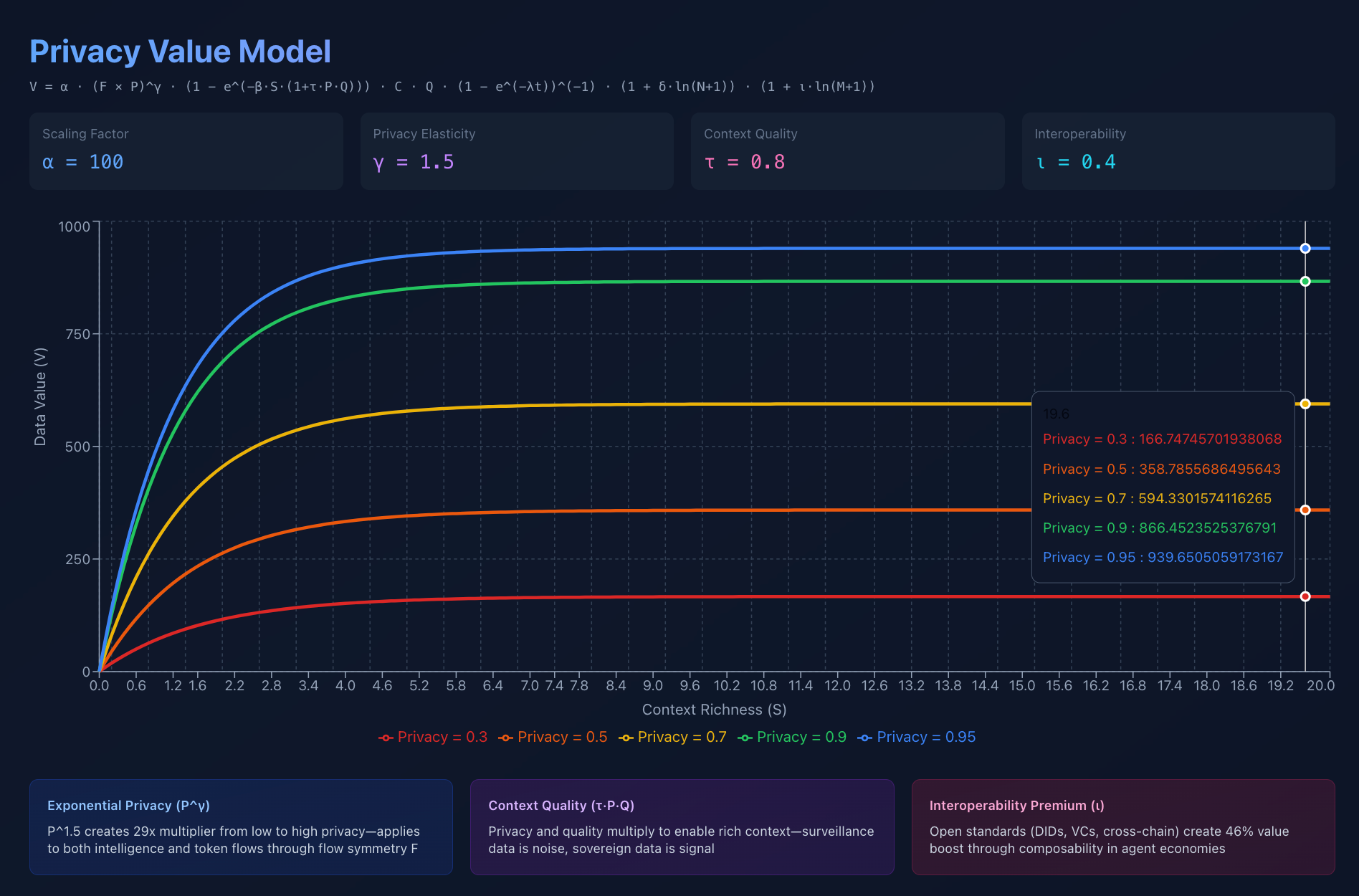
Privacy Value Model v1
Here’s the equation that quantifies privacy’s value:
V = α · P^γ · (1 - e^(-βS)) · C · Q · (1 - e^(-λt))^(-1) · (1 + δ·ln(N+1))
Translation:
Data value = Privacy × Control × Quality × Context × Freshness × Network effects
Privacy Value Model v2*
V = α · P^γ · C · Q · S · e^(-λt) · (1 + N/N₀)^k
* (added after feedback from Pengwyn 30/10/25)
Privacy is Value.v2. the Swordsman, the Mage, the Drake, and capturing the 7th Capital

I’ve spent the past couple of weeks at the agentic internet workshop AIW, IIW 41 and BGIN un*conferences, and this privacy = value model has been spinning in my head the entire time. Every session, every conversation, I found myself musing on how new insights could refine it.
Breaking it down:
*P (Privacy): Cryptographic protection—ZK proofs, encrypted compute, selective disclosure (0 to 1)
*C (Control): User sovereignty—you hold the keys, you own the agent (0 to 1)
*Q (Quality): Verifiability—onchain credentials, attestations, cryptographic proofs (0 to 1)
*S (Context): Social richness—interactions, relationships, history (0 to ∞)
*t (Time): Freshness—agents need current data, not stale aggregates
*N (Network): Decentralized participants validating and coordinating
P^γ means privacy is exponential, not linear.
Going from 90% to 95% privacy isn’t 5% better. It’s exponentially better.
again… isn’t just me shouting a philosophical choice steeped in cypherpunk legacy, its a future economic reality for all of us.
Privacy Can’t Be Retrofitted
Here’s what breaks most privacy initiatives:
You can’t build on surveillance architecture and add privacy later.
When systems are designed for data extraction, privacy features actively fight the infrastructure.
You get:
Technical debt that blocks implementation
Data has already leaked into broker networks (can’t unspill that)
Architecture incompatible with ZK proofs, encrypted compute, and distributed consensus
User trust is already broken
the modern data serfdom is already real, and people are just starting to wake up to this.
Privacy must be in the foundation.
In the model, P(privacy) and C(control) multiply.
You can’t start at P=0.2, C=0.1 and “upgrade” to P=0.9, C=1.0.
The ceiling is baked into your architecture.
Systems built with surveillance at the core hit ceilings around P=0.4-0.5.
They physically can’t go higher without rebuilding from scratch.
Systems built with privacy from day one can reach the sovereignty zone (P>0.8, C>0.8) and capture exponential value.
This is why “we’ll add privacy later” isn’t a roadmap.
It’s cope.
As agents proliferate, the systems architected for privacy from inception will dominate. The ones trying to retrofit will structurally lose.
Two Paths: Centralised vs Sovereign
Let’s run the numbers over 24 months of agent adoption.
Path One: Centralised Agent Architecture
Month 0: Default settings on major platforms.
Privacy = 30%, Control = 20%.
Month 6: Your agent integrates across services, learns from everything. Platform owns the model, the data, the decisions.
Privacy = 25%, Control = 15%.
Month 12: Powerful agent, total black box. Can’t audit, can’t export, can’t verify.
Privacy = 20%, Control = 10%.
Month 18: Agents everywhere, making predictions and trades using data you never explicitly shared.
Privacy = 15%, Control = 8%.
Month 24: Your digital twin exists entirely in platform infrastructure. Zero keys, zero control, zero verification. Maximum convenience.
Privacy = 10%, Control = 5%.
Terminal value: ~50
Why so low? 🧙♂️
Flow symmetry (F=1.0) but both flows are exposed.
Context appears high (S=15) but quality-adjusted drops to S_effective=15.4 due to unverified, polluted data.
Proprietary systems (M=2) limit interoperability.
Path Two: Sovereign Agent Architecture
Month 0: Same starting point.
Month 6: Privacy-first tools. Brave/Firefox, Signal, VPN. Basic agent with privacy protections.
Privacy = 50%, Control = 35%,
Flow symmetry maintained, beginning interoperability. Value +67%
Month 12: Self-sovereign identity. Hardware wallet, DIDs, password manager. Agent operates under your cryptographic authority.
Privacy = 65%, Control = 60%,
adopting open standards (M=5). Value +210%
Month 18: Decentralised storage. ZK authentication. Verifiable credentials that your agent presents.
Privacy = 80%, Control = 85%,
full standards adoption (M=10). Value +520%
Month 24: Fully sovereign agent on privacy-preserving compute. ZK proofs, revocable credentials, decentralised infrastructure. Manages crypto assets with the same privacy as identity.
Privacy = 95%, Control = 100%,
maximum interoperability (M=15). Value +1600%
Terminal value: ~850
Why so high? 🧙♂️
Flow symmetry (F=1.0) with both flows highly protected.
Context appears lower (S=14) but quality-adjusted jumps to S_effective=24.1 due to verified, trusted data.
Open standards (M=15) multiply value through composability.
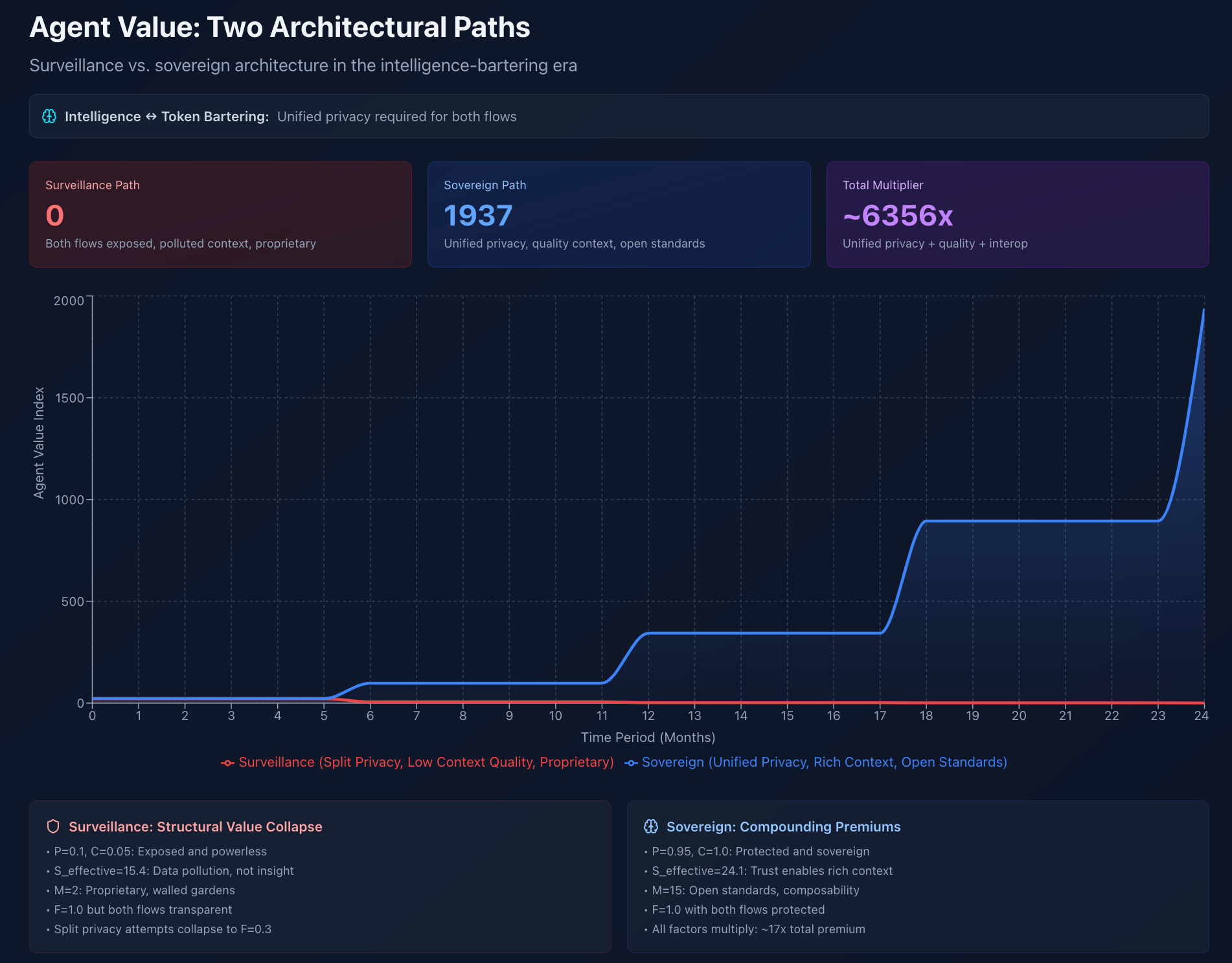
The gap isn’t just a cypherpunk legacy and ideology. It’ll become your economic reality.
Notice three critical factors:
Flow symmetry: Path Two only works because both intelligence and token flows maintain unified privacy. Attempt to split them and F collapses to ~0.3, destroying value.
Context quality: Surveillance path has MORE raw data (S=15 vs S=14) but LOWER effective context (15.4 vs 24.1) because unverified data is noise, not signal.
Interoperability: Proprietary systems (M=2) create 1.44x multiplier. Open standards (M=15) create 2.11x multiplier. Standards adoption is a 46% value increase.
Path Two only reaches P=0.95, C=1.0, because privacy was designed in from the start. If you tried upgrading a
Path One system, you’d hit ceilings around P=0.4-0.5, and F would never reach 1.0 due to architectural incompatibility between flows.
When Data is Money: a Unified Framework
It’s time we come to terms with the convergence of data and money, especially when it comes to on-chain systems.
The ledger (blockchain) is just there to record who owns it when, immutably, not really what it’s worth to humans or machines, that changes from peer to peer.
Whether you’re protecting:
Information (identity, credentials, agent instructions)
Financial value (tokens, transactions, balances)
The cryptographic foundations are identical:
Privacy (P): Confidential transactions = Selective disclosure for identity
Control (C): Self-custody of keys works the same for tokens and credentials
Quality (Q): Verifiable transactions on-chain = Verifiable attestations in identity systems
Immutability: Blockchain’s distributed ledger provides tamper-proof history for both
Zcash and Privacy Pools: The Model in Action
Traditional blockchain (Bitcoin, Ethereum):
P = 0.2-0.3 (pseudonymous but fully traceable)
C = 0.8 (self-custody, but transparent)
Q = 1.0 (verified, immutable)
Value: Moderate
Zcash shielded transactions:
P = 0.95 (zk-SNARKs hide sender, receiver, amount)
C = 1.0 (full self-custody)
Q = 1.0 (cryptographically verified)
Value: Maximum
The difference? Zcash built privacy in from the start.
You can’t take Bitcoin and “add” zk-SNARKs later. The architecture doesn’t support it.
Privacy pools show how to tune the model and make up for the transparency on Ethereum by default:
Allow proving you’re not associated with illicit funds or a part of a group of mutually aligned funds.
ZK proofs demonstrate “clean” history without revealing transactions
Graduated privacy: full confidentiality + provable dissociation from unwanted associated addresses
Privacy pools parameters:
P = 0.85-0.9 (privacy with selective disclosure for compliance)
C = 1.0 (user-controlled pool membership)
Q = 0.95 (cryptographic proofs of dissociation)
Even at P=0.85 vs P=0.95, you still capture enormous value compared to transparent transactions.
Because P^1.5 is exponential.
Convergence: Why Privacy Goals Unify in the Agent Economy
Here’s where it gets interesting. (lol, at least i think so)
Your AI agent managing financial assets needs the same privacy infrastructure as your AI agent managing identity credentials.
But the real convergence happens when agents start bartering intelligence for tokens.
Picture this: Your research agent shares specialised intelligence with another agent network, contributing insights, analysis, and computational resources. In return, you receive tokens representing that value.
On one side of the transaction: identity credentials and intelligence (who you are, what you know, what your agent can prove)
On the other side: tokens representing money (compensation for that intelligence)
Both flows require an identical privacy infrastructure. But here’s the critical insight the model reveals through Flow Symmetry (F):
You cannot have private intelligence with transparent tokens.
If P_intelligence = 0.8 but P_tokens = 0.3, the effective flow symmetry F = 0.3/0.8 = 0.375. This doesn’t just reduce value, it collapses it.
The model becomes:
V = α · (0.375 × 0.8)^1.5 × ... = α · (0.3)^1.5 × ...
Your claimed 80% privacy on intelligence drops to effective 30% privacy because the token flow leaks. Split privacy architectures leak from both ends.
For the intelligence your agent shares:
ZK proofs to verify expertise without revealing proprietary methods
Selective disclosure to prove credentials without exposing entire history
Verifiable attestations showing quality of contributions (Q=0.95+)
Self-custody ensuring you control what gets shared and when (C=1.0)
For the tokens you receive:
Privacy-preserving transactions hiding compensation amounts
Self-custody of keys controlling those assets
Verifiable onchain records proving legitimacy without surveillance
Same cryptographic protection as the credentials
When AI agents barter, trading intelligence for tokens, contributions for compensation, expertise for value, the privacy requirements become inseparable.
You can’t have:
Your agent shares intelligence privately while receiving tokens transparently (both sides leak)
Transparent credentials but private payments (credential metadata reveals payment patterns)
High-quality verified contributions (Q=0.95) without cryptographic protection (P=0.95)
The same ZK proof that hides your transaction amount can hide your identity attributes while proving claims about them.
The same self-custody model that protects your tokens protects your credentials.
The same verifiable on-chain system that ensures payment legitimacy ensures credential validity.
And here’s what the model reveals about context quality: More surveillance doesn’t mean richer context.
Surveillance path: S_raw = 15 (lots of data) but S_effective = 15 × (1 + 0.8 × 0.1 × 0.3) = 15.4 (low quality context)
Sovereign path: S_raw = 14 (less data) but S_effective = 14 × (1 + 0.8 × 0.95 × 0.95) = 24.1 (high quality context)
Privacy and quality multiply to enable genuinely rich context through trust. Surveillance creates data pollution, not insight.
Finally, interoperability (M) determines whether your agent can actually operate in the bartering economy:
Proprietary systems: M = 2, Interoperability multiplier = 1.44x
Open standards (DIDs, VCs, cross-chain): M = 15, Interoperability multiplier = 2.11x
Standards adoption is a 46% value increase because agents need to coordinate across networks.
This is why projects at the intersection, verifiable credentials for DeFi, reputation systems for on-chain lending, private agents managing crypto while sharing intelligence, aren’t combining two separate domains.
They’re recognising that in an agent economy where intelligence and money flow bidirectionally, cryptographic privacy, distributed consensus, and user control apply universally to value.
Whether that value is information or money becomes irrelevant. It’s all just value requiring protection, and the protection must be unified.
The model holds across both. P^γ × C × Q creates exponential value multiplication, whether you’re protecting your agent’s intelligence contributions or the tokens you receive for them.
As agents proliferate and begin bartering at scale, millions of intelligence exchanges for token compensation happen autonomously while you sleep, the systems built with unified privacy from inception will dominate.
Systems trying to “add privacy” to one side while keeping the other transparent will leak from both ends.
Why This Matters in Agent-to-Agent Systems
When agents are ubiquitous:
Intelligence bartering: Your research agent contributes specialised analysis to a distributed AI network and receives tokens. Do you want competitors to see what intelligence you’re selling and for how much? Or ZK proofs that verify contribution quality while keeping both your expertise and compensation private?
Negotiation: Your agent negotiates pricing with a merchant’s agent. Do you want every tactic visible to the merchant’s parent company? Or ZK proofs that validate claims without revealing strategy?
Multi-party coordination: Health agent coordinates with fitness, nutrition, and diagnostic agents. Centralised database? Or selective disclosure with cryptographic attestation?
Credential verification: Agent proves you’re qualified for a loan, job, or network access. Share your entire history? Or ZK credentials proving specific claims (”income > $X”) without revealing underlying data?
Financial operations: Agent manages your portfolio, executes trades, and provides liquidity. Is every transaction visible to surveillance? Or privacy pools and shielded transactions, maintaining confidentiality while proving legitimacy?
Autonomous action: The Agent acts while you sleep. If compromised, can you audit? Revoke authority? Or is it a black box?
Privacy-preserving architecture isn’t preferable. It’s necessary for the system to work for you.
Otherwise, become a victim of the modern serfdom to feed AI’s insatiable hunger for information on its path to superintelligence.
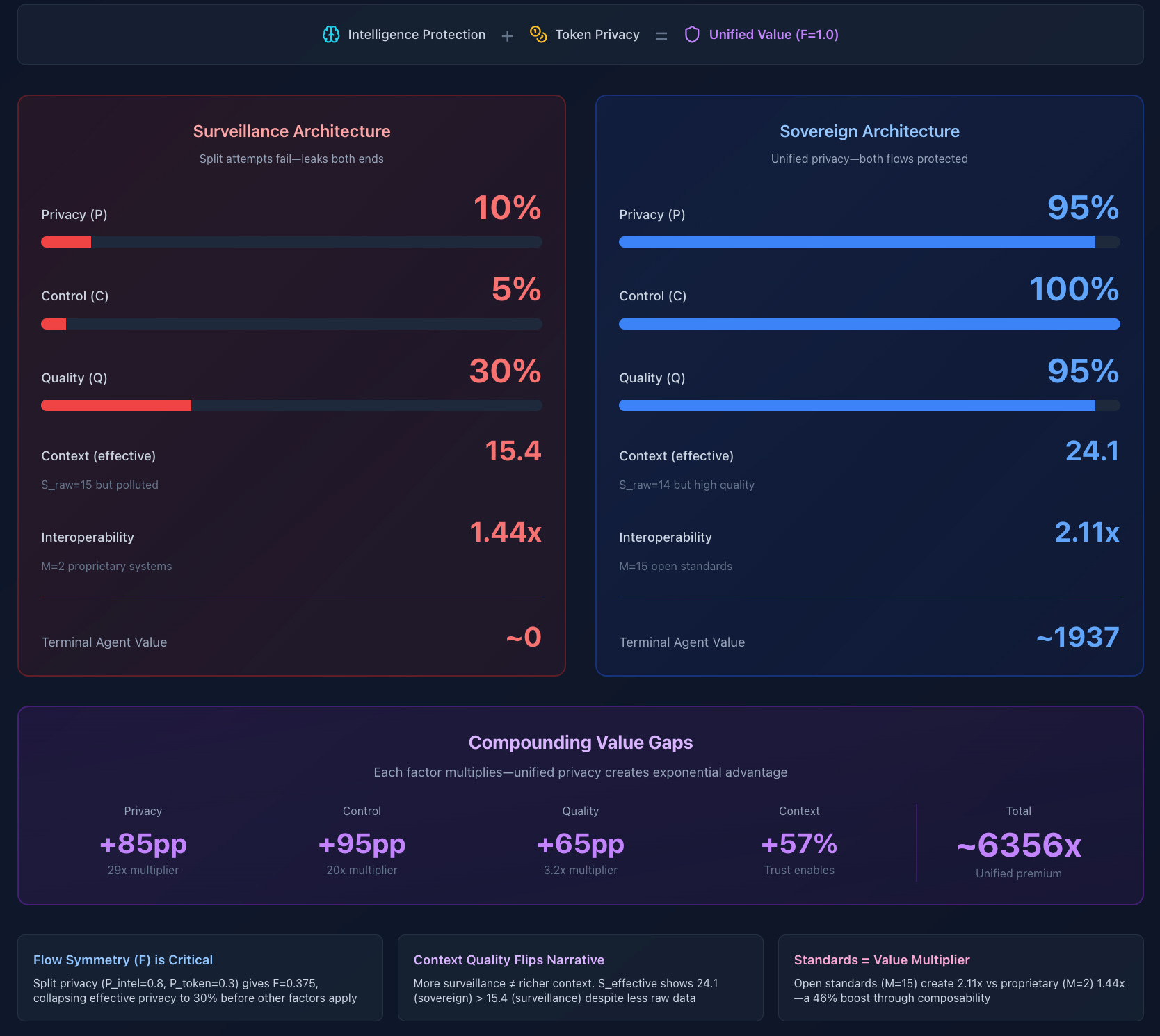
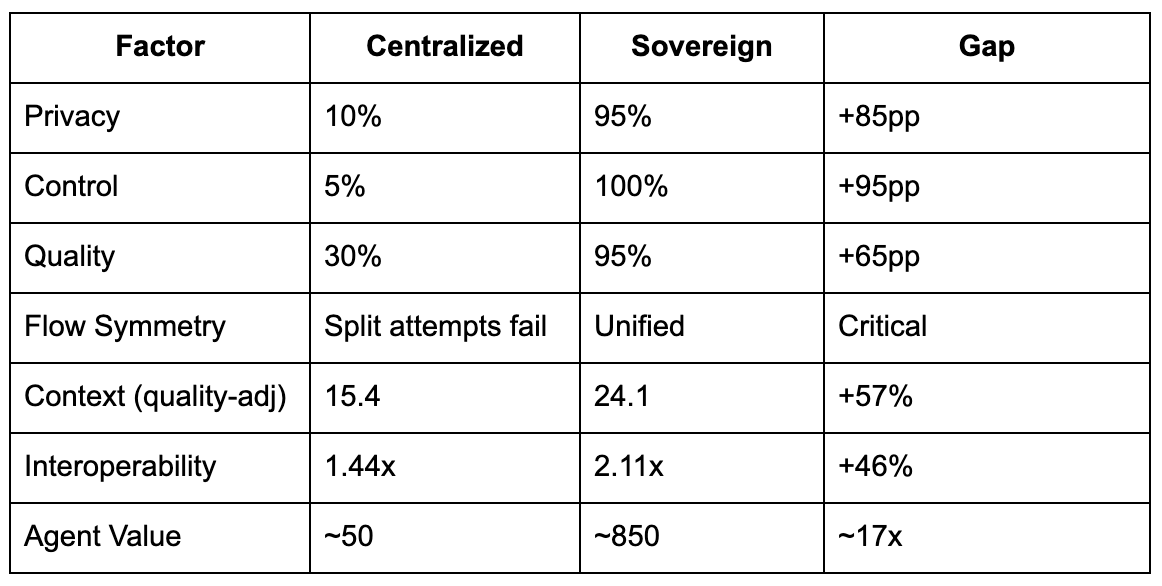
Privacy is normal because without it, agents can’t be autonomous, verifiable, or trustworthy.
Btw, the infrastructure already exists
Self-Sovereign Identity (DIDs),
Zero-Knowledge Proofs,
Verifiable Credentials,
Decentralised Storage (IPFS, Filecoin),
Hardware Wallets,
Private Compute,
Privacy-Preserving Blockchains/protocols (Zcash, privacy pools),
Smart Contract Platforms with privacy enhancements
It’s all there in many forms for you to use.
The question isn’t “can we build this?”
The question is: “How fast will economics force adoption?”
A good example of this is the work I’m doing, building the multi-agent research system for BGIN: Decentralised Open Source Pathways (more on this soon).
Value Decomposition: Where the Multiplier Comes From
Flow Symmetry (F):
Surveillance: Both flows equally exposed, F = 1.0, but...
Split attempt: P_intelligence = 0.8, P_tokens = 0.3, F = 0.375 (collapses value by 62.5%)
Sovereign: Both flows protected, F = 1.0, and P is high
Critical insight: You can’t split privacy between intelligence and tokens
Privacy Component (P^1.5):
Centralized: 0.1^1.5 = 0.032
Sovereign: 0.95^1.5 = 0.926
Multiplier: 29x
High privacy isn’t incrementally better. It’s categorically different. ZK proofs don’t give 2x the value of basic encryption. They give 20-30x. True for identity claims and financial legitimacy through privacy pools. And if you try split privacy, F kills the value before the exponent even applies.
Control Multiplier (C):
Centralized: 0.05
Sovereign: 1.0
Multiplier: 20x
Holding the keys, revoking agent authority, auditing decisions, exporting everything, isn’t slightly higher value. It’s an order of magnitude higher. Same keys control tokens and credentials.
Quality Factor (Q):
Centralized: 0.30 (unverifiable, broker-aggregated)
Sovereign: 0.95 (cryptographically attested, verifiable)
Multiplier: 3.2x
Agents need high-quality training and inference data. Verifiable credentials beat surveillance data because they’re provably accurate. Blockchain immutability ensures tamper-proof history.
Context Richness (Quality-Adjusted):
Surveillance: S_raw = 15, but S_effective = 15 × (1 + 0.8 × 0.1 × 0.3) = 15.4
Sovereign: S_raw = 14, but S_effective = 14 × (1 + 0.8 × 0.95 × 0.95) = 24.1
Multiplier: 1.56x
This reveals surveillance’s lie: more data ≠ richer context. Unverified, polluted data is noise.
Privacy and quality multiply to create genuinely valuable context through trust.
Interoperability Premium (M):
Surveillance: Proprietary systems, M = 2, I = 1.44
Sovereign: Open standards (DIDs, VCs, cross-chain), M = 15, I = 2.11
Multiplier: 1.46x
Agent economies require cross-platform coordination.
Standards adoption is a ~46% value multiplier.

Multiply these together: 17x gap. This is how privacy is normal. The economics demand it.
But here’s what makes the gap even more dramatic: These multipliers compound.
Start with split privacy (F = 0.375), and you’ve already lost 62.5% before other factors apply. Add low P, low C, low Q, polluted context, and poor interoperability; each one multiplies the deficit.
Conversely, unified privacy (F = 1.0) with high P, full C, verified Q, trust-enabled rich context, and open standards, each one multiplies the premium.
The 17x isn’t additive. It’s multiplicative. And it’s conservative, real-world adoption of truly sovereign architectures may show even larger gaps as agent economies scale.
What This Means As Agents Proliferate
Building identity infrastructure?
Design for C=1.0 and P>0.8 from day one. Non-custodial isn’t just ethical, it’s economically superior. Again… Privacy can’t be retrofitted.
Developing AI agents?
Build on privacy-preserving rails from the foundation. ZK proofs, verifiable credentials, encrypted compute. The premium grows as agent-to-agent systems proliferate. Same architecture for identity and financial operations.
Deploying enterprise AI?
Sovereign agent architecture creates differentiated value. Private agents with user-controlled data unlock use cases that surveillance models physically can’t serve. Privacy pools and shielded transactions aren’t limitations, they’re competitive advantages.
Building blockchain infrastructure?
Identity and finance converge in the agent era. Same ZK proofs, same distributed consensus, same immutable ledgers serve both. Design for privacy from inception, retrofitting is expensive and often impossible.
User preparing for the agent era?
Start building your sovereign stack now. Hardware wallet, DID, verifiable credentials. Each step compounds. Use privacy-preserving tools for identity and finances, they’re built on the same foundations.
paving the privacy path
You don’t need P=0.95 overnight. Privacy-preserving identity is incremental:
Month 1: Privacy-first browser, messaging, VPN (+30-40% value)
Month 3: Hardware wallet, password manager, first DID (+100% value)
Month 6: Decentralised storage, verifiable credentials, privacy-preserving financial tools (+200% value)
Month 12: ZK authentication, private AI agent setup, self-sovereign compute, privacy pools (+400% value)
Each step increases privacy, control, and quality. Each step multiplies the value. As agents proliferate, each step becomes essential.
But remember: Start with privacy in the foundation. Each step builds on the last. You can’t skip to month 12 if months 1-6 are built on surveillance.
Privacy is Normal
Autonomous agents will represent billions of people across billions of interactions, managing identity, handling credentials, executing financial transactions, and negotiating on our behalf.
The identity systems we build now determine whether those agents serve humans or platforms.
Privacy-preserving, user-controlled, verifiable identity systems create 17x more value than surveillance alternatives.
Not because privacy is a luxury. Privacy is the foundation of functional agent systems.
You can’t have autonomous agents without user control.
You can’t have trustworthy agents without verifiable credentials.
You can’t have multi-party coordination without zero-knowledge proofs.
You can’t have accountable agents without auditable decisions.
You can’t have financial privacy without cryptographic protection.
You can’t retrofit privacy into surveillance architecture.
You can’t split privacy between intelligence and token flows…they leak together.
You can’t get rich context from surveillance data; it’s pollution, not insight.
You can’t operate in agent economies without interoperable standards.
Privacy is normal.
It’s the architecture that makes everything else possible. Privacy is a measured goal.
Whether we’re talking about data or money, the foundations are the same:
cryptographic protection, distributed consensus, immutable records, and user control.
Blockchain-based systems show this convergence; the same tools enabling private transactions also enable private credentials. The same ZK proofs hiding payment amounts hide identity attributes.
As agents proliferate, systems embracing this truth, building sovereignty and privacy into their foundation from day one, will create the most value. Systems trying to add privacy later will structurally lose.
The choice is clear. The tools exist. The economics prove it.
Let’s build identity systems worthy of the agentic everything era we’re entering.
Bgin’in to build this into reality
ideally this isn’t just theory. It’s the foundation of practical work happening right now at BGIN (Blockchain Governance Initiative Network).
When designing BGIN’s AI framework, we’re embedding this privacy at inception, into the core of how we think about AI governance, decentralised identity, and privacy-preserving systems. The model you’ve seen here shapes our approach to:
Identity architecture for AI agents - designing sovereign identity systems where P and C aren’t compromises but defaults
Reputation economics and verifiable credentials - building on-chain systems where Q=0.95+ is the baseline, not an aspiration
Privacy-preserving compute frameworks - ensuring AI agents can coordinate and transact without surveillance as the operating system
Governance mechanisms - creating structures where user control (C=1.0) is enforced cryptographically, not promised through policy
We’re building the architecture for the purpose of blockchain governance and standards creation, because, well, that’s what I’m into.
But this can be used as a framework for any research or agentic activity.. and much more hopefully.
If you’re working on decentralised identity, private AI agents, blockchain-based credentials, or privacy-preserving infrastructure, and you want to understand how the economics of sovereignty actually work.
This model is a neat starting point.
Privacy isn’t optional. It’s optimal. And the economics make that undeniable.
Want to explore the model yourself? Copy this article into your LLM and ask it to build an interactive artifact showing how privacy, control, quality, and network effects combine to create agent value. Test scenarios from transparent blockchains to privacy pools. See how Zcash-level privacy (P=0.95) compares to pseudonymous systems (P=0.3).
I’ll host an interactive version soon too I think, just need to vibe that out.
Privacy is normal. Let’s make it universal, before it’s too late.
One More Thing: Your Reality Is Being Reconstructed
Here’s what we haven’t talked about yet.
AI isn’t just processing your data. It’s building generative models of you, digital twins that can predict your decisions, simulate your behaviour, and participate in scenarios while you sleep.
Every data point is training data for an ultimate reconstruction of your reality.
The question isn’t whether this happens. It’s already happening.
The question is: who owns that substrate?
In a short amount of time, digital twins will be standard infrastructure.
Markets will emerge for licensing access to high-fidelity decision patterns, training AI on verified behaviour, and simulating scenarios on twin populations.
The architectural decisions you make now…
surveillance (P=0.1, C=0.05) or
sovereign (P=0.95, C=1.0)
determine whether you own your reconstructed reality or become raw material in someone else’s simulation economy.
The 17x value gap we calculated?
That’s just for data today. Reality reconstruction value multiplies that gap.
High-fidelity sovereign twins will capture exponential premiums over low-fidelity surveillance approximations.
In an economy where authenticity is scarce, verified sovereignty is everything.
I’d like to thank a close friend, Buko, for pushing me to write this concept down properly, via regular debate and triggering me with the statement ‘privacy is dead, gave up on that years ago’.

Oh, also, you can just do things,
I’m just another swordsman.